
Atle Winther
Blog





Kunstig intelligens og dine data
Et lille skriv om kunstig intelligens og indsamling af data, og vigtigheden i at passe på hvem vi giver vores data til.
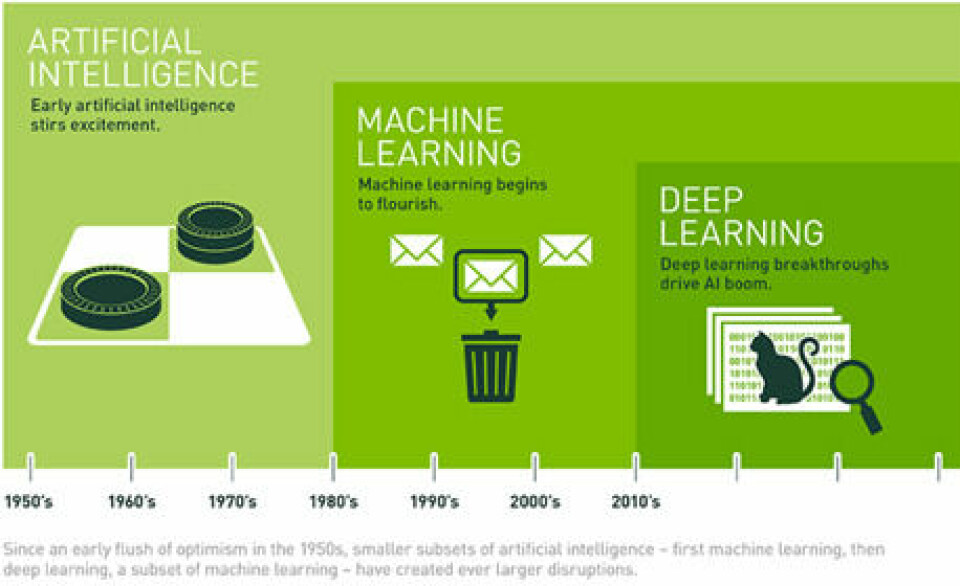
Kunstig intelligens er i løbet af de seneste 60 år gået fra at være en akademisk diciplin, forundt en lille elite, til i dag at blive benyttet af virksomheder, organisationer og myndigheder verden over. Der er flere faktorer som er årsag til dette. Bl.a. har vi i dag langt billigere og kraftigere teknologi til rådighed. Faktisk kan de fleste helt almindelige computere, som kan købes for et par tusinde, arbejde med kunstig intelligens.
Det er gået stærkt. Man taler om en ny industriel revolution, hvor teknologier ikke længere behøver at blive håndteret manuelt. Et eksempel på dette er de selvkørende biler, som ved hjælp af computer vision navigerer rundt på gader og stræder.
Wikipedia specificerer en teknisk/industriel revolution således(*1):
“A technological revolution is a period in which one or more technologies is replaced by another technology in a short amount of time. It is an era of accelerated technological progress characterized by new innovations whose rapid application and diffusion cause an abrupt change in society.”
Kunstig intelligens I hverdagen
I hverdagen taler Siri og Alexa til os, vi ser Netflix der anbefaler film til os, baseret på algoritmer, spamfiltrene i vores mail-programmer klassificerer, hvorvidt posten i vores indbakke er spam eller ham, og uden at vi tænker over det bliver vores kreditkort sikret imod digital svindel, prototyper på selvkørende biler kører som nævnt rundt i gaderne. Og skulle man blive ramt af sygdom, bliver visse typer skanninger udregnet med en sådan nøjagtighed, at vi kan klassificere præcise positioner og former på eksempelvis tumorer. Alt sammen pga. kunstig intelligens. Derudover peger meget på, at vi snart kommer til at erfare øget overvågning I Danmark(*2), som – med en lovændring - giver myndigheder lov til at benytte, den kritiserede ansigtsgenkendelse, som mange eksperter og aktivister mener krænker retten til privatliv og reelt ikke er til megen gavn i efterforskningssager.
Den kunstige intelligens - The imitation game
Turing-testen, beskrevet af Alan Turing I 1950 (*3), bygger forenklet på tanken om, hvorledes mennesket kan skelne mellem menneske og maskine inden for fjernkommunikation. Turing kalder teorien for the imitation game:
"“It is played with three people, a man (A), a woman (B), and an interrogator (C) who may be of either sex. The interrogator stays in a room apart front the other two. The object of the game for the interrogator is to determine which of the other two is the man and which is the woman. He knows them by labels X and Y, and at the end of the game he says either "X is A and Y is B" or "X is B and Y is A."”
Tanken om at bygge maskiner, der imiterer menneskelig adfærd, bliver af mange opfattet som starten på kunstig intelligens. Programmet ELIZA var det første program som tog omdannede Turing-testens teori til praksis. Deep Blue, der slog stormesteren i skak, Gary Kasparov, fik for alvor slået fast hvordan kunstig intelligens er i stand til at imiterer et menneske så overbevisende, at maskinen slår stormesteren i skak.
Sidenhen har man kategoriseret en række underkategorier inden for kunstig intelligens, heriblandt:
- Machine learning, som er koncentreret om statistisk modellering af data, hvor vi "fodrer" vores maskine med indsamling af data, som efterfølgende ser mønstrer og danner sammenhænge i vores data. Og måske kan vi ligefrem bygge en model, som kan forudsige fremtiden for os.
Med fingrene ned i maskineriet
Lad os nu få fingrene ned i maskineriet. I følgende eksempel har jeg et dataset med i alt 150 billeder af blomsten Iris(*4) fordelt på 3 klasser, som hver især repræsenterer arter af iris-slægten med hhv. 50 billeder I hver klasse. Vi ønsker os en model, som kan klassificere følgende 3 arter af iris-slægten:
Iris Verginica
Iris Versicolor
Iris Vertosa
Træning, test og lidt om algoritmer:
Ved at se på de 3 iris-arter, kan man se at der er forskel på kronbladet(petal) og de underliggende bægerblade(sepal). Endvidere kan vi se, at kronbladet hos de tre klasser har stor variation i bredden ude på spidserne.
Vi forsøger nu at prøve med hjælp af forskellige algoritmer, at finde en god løsning på en model, som udregner med den lavest mulige fejlprocent, og dermed bliver det mest troværdige produkt. I første omgang træner vi derfor vores dataset og ser om det skulle indeholde fejl(overfodring eller for få data, dårlig indsamlede data, menneskelige fejl mv kan være årsager).
Lidt teknisk snak, som jeg ikke forventer du skal kunne, men som jeg alene skriver om, fordi brugen af algoritmer er et væsentligt element af machine learning. I dette eksempel benytter jeg algoritmen, Linear Regression(*5) i testen. Algoritmen skal bruges til at vi kan skelne arten Virginica fra Setosa og Versicolor, mens jeg I det sidste eksempel benytter Softmax Regression/multinomial logistic regression(*6) til at klassificere hver enkelt blomsts karakteristika. Jeg har lagt koden på Github(*7).
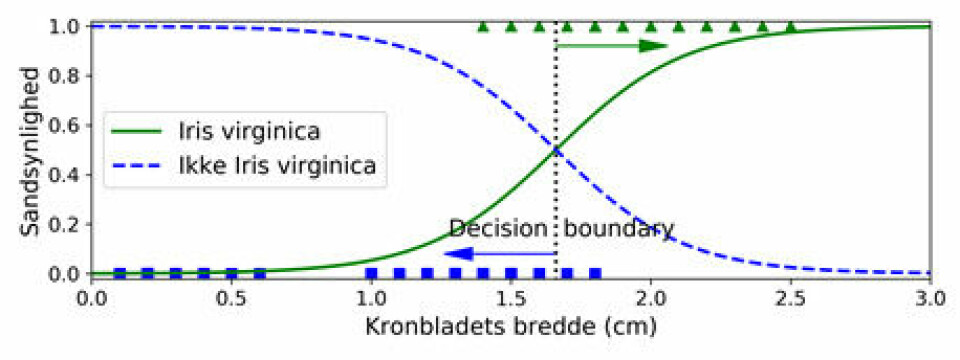
Virginica
Vi kan her se, at vores model estimerer, at Iris Verginicas(trekanterne) kronblad varierer fra 1,4 cm til 2,5 cm i bredden, mens de andre blade(firkanterne) har en smallere bredde. Og som sandsynligheden indikerer, er det med en ret høj sikkerhed på > 90%.
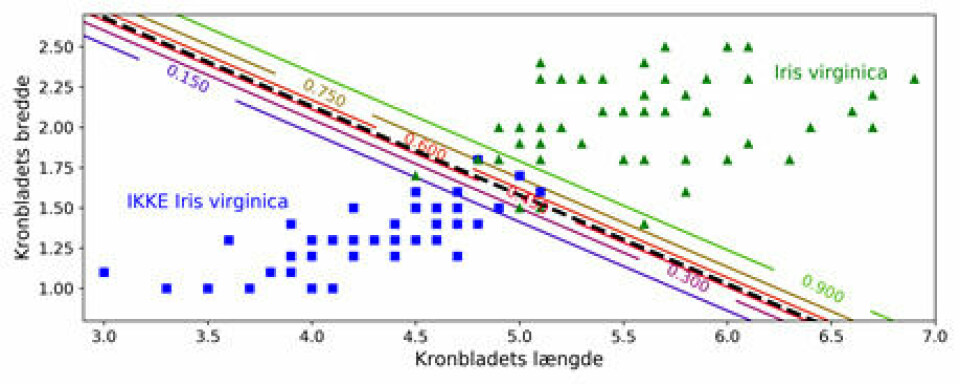
Vi kan også se hvordan længden og bredden i cm, fordeler sig mellem Virginica vs Setosa og Versicolor. Det ses tydeligt, at Virginica både har et længere og bredere kronblad end de andre.
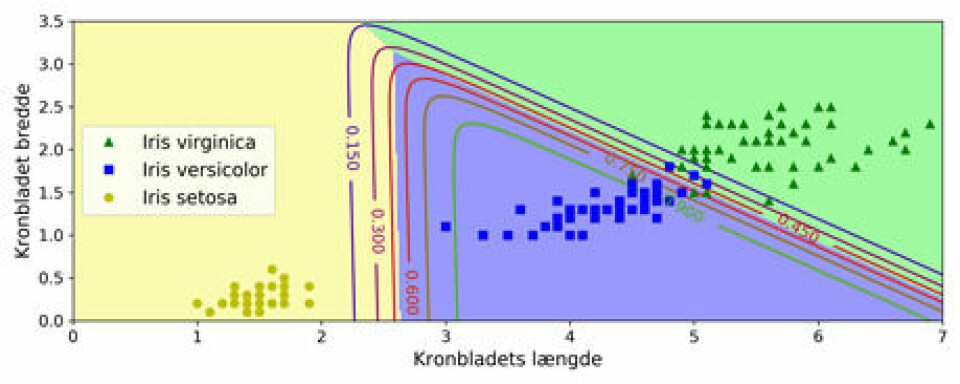
I det sidste eksempel klassificeres de tre iris-arter. Virginica ligger på omkring 5 cm i længde og 2 cm i bredde. Versicolor på 3,5 cm I længde og 1,5 i bredde. Setosa ligger på 1 cm i længden og 0,5 cm i bredden.
Til sidst udregner vi sandsynligheden for at blad på 5 cm i længden og 2 cm I bredden rent faktisk er arten Virginica. Out[65] siger kort og godt, at der er 94% sandsynlighed for at et blad med denne geometri er arten Virginica. Testen er klaret med en relativ lav fejlprocent.
Man skal ikke blindt tro på, hvad en machine learning model siger er sandheden. Så er du i nærheden af en iris, kan du måske ligefrem kunne teste om denne model udsiger korrekte prognoser på de 3 slægter i iris-familien.
Der findes desuden mange andre underkategorier inden for kunstig intelligens. Fx Natural Language Processing(NLP), speech recognition, robotics og computer vision.
Disse kategorier flyder ofte ind i mellem hinanden(fx er NLP lige så ofte et integreret element inden for computer vision, som det er en selvstændig disciplin). Og når det kommer til træning af modellerne, kan vi bruge supervised learning, unsupervised learning, reinforcement learning, curriculum learning, semi-supervised learning mf. Og derudover skal man være skarp på valg af algoritmer, der skal gøre hele processen med bearbejdelsen af data så smidig som mulig. I min optik er det ikke vigtigt om vi kalder det for det ene eller det andet.
Deep learning og neurale netværk
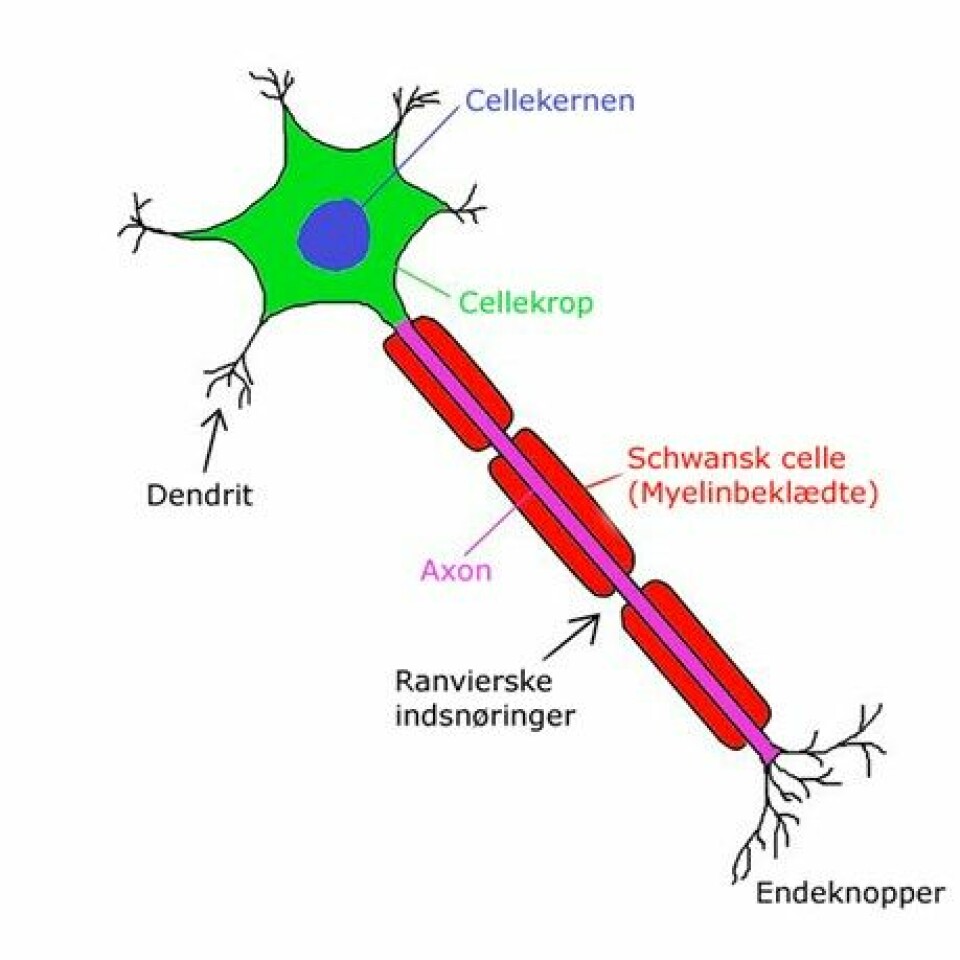
En anden benyttet disciplin inden for kunstig intelligens er deep learning og neurale netværk; en underkategori af machine learning. Neurale netværk er inspireret af den biologiske hjerne, hvor neuronens dendritter modtager impulser fra andre neuroner, og transmiterer signaler videre gennem axon'en, afhængig af om den synaptiske spændingsforskel er høj nok. Neuroner som er I hvile vil fx have en lav elektrisk spænding, og dermed vil de ikke sende signaler til andre neuroner. Det er altså et alt eller intet-forhold mellem neuroner. Enten sender de et signal videre eller også gør de det ikke.
Det er lige præcis dette som deep learning forsøger at immitere. Også her findes der i øvrigt en række forskellige modeller (neural networks, convulotional neural networks, Style Based Gans etc.).
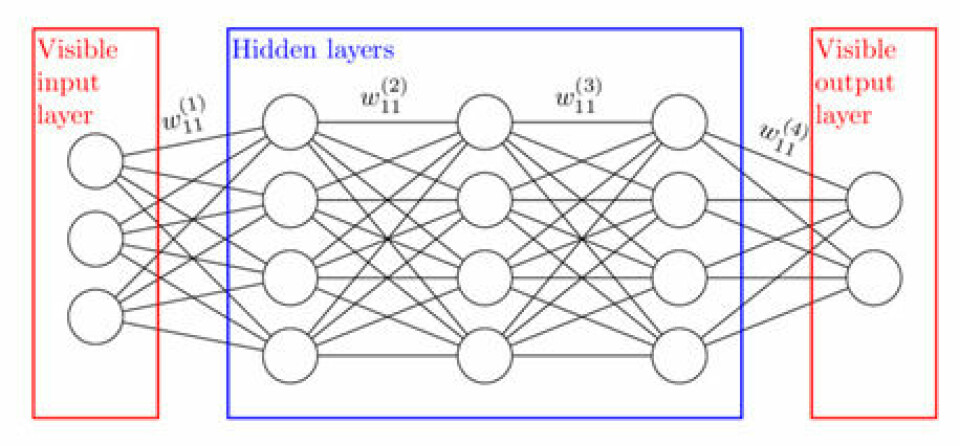
Forenklet sagt, modtager et computationalt neuralt netværk data fra omverdenen, som den bearbejder vha lag af neuroner, som transmiterer data I mellem hinanden for at opnå et ønsket resultat.
Ovenstående billede viser hvorledes data(fra den røde input-boks) transporteres videre til den blå boks, der består af flere lag af neuroner. W står for synaptic weight og lader sig altså i lighed med den biologiske hjerne styre af vægten med den højeste spænding, som sender data videre til den næste neuron.
Et eksempel er at vi ønsker, at et netværk skal genkende en kat. Herefter træner vores model gentagende gange i at genkende billeder af forskellige katte, i forskellige positioner, filmet fra forskellige vinkler. På samme måde er det, at de selvkørende biler træner i at blive bedre og bedre til at tolke geometriske objekter.
Et par sjove eksempler på neurale netværk er Googles Quick Draw(*8) og This person does not exists(*9).
Er der intelligens?
Sammenfattet kan man ikke tale om nogen biologisk intelligens. Et neuralt netværk er bygget op omkring en model, som alene er koncentreret omkring den synaptiske process imellem neuroner. Dyrs neuroner og centralnervesystemer er betydeligt mere komplekse og består desuden af en lang række kemiske processer og hjernestrukturer. En maskine føler ikke noget, mens vi som mennesker har et limbisk system, som bl.a har forbindelse til. vores amygdala der har indflydelse på om vi oplever angst, glæde, vrede og forelskelse mv. På den måde er vi langt mere komplekse.
Men spørgsmålet om, hvorvidt en maskine kan være intelligent er interessant, og lægger op til både filosofiske, biologiske og samdfundsfaglige debatter. For reelt set udfører maskinen jo opgaver der kan opfattes intelligente.
Nogle vil plædere for, at der I hvert fald er tale om en form for linær intelligens.
Potentialet
Kunstig intelligens kommer til at forandre verden omkring os, og der er bestemt potentiale til at den kan gøre verden til et bedre sted. Vi kan lette arbejdet på sygehuse verden over. Især de steder, hvor der er akut mangel på sundhedspersonale, vil kunstig intelligens være en frugtbar løsning, idet det vil kunne frigive ressourcer. Og vi vil kunne bygge smarte logistiske modeller til at reducere flys forbrug af brændstof. Og der arbejdes flittigt på intelligente systemer, der kan advare imod skovbrande og forebygge disse.
Transportfagene vil hurtigt opleve kunstig intelligens. Fx vil mekanikere i fremtiden komme i berøring med selvkørende biler, social og sundheds-assistener, sygeplejersker, fysioterapeuter og lignende faggrupper, som dagligt laver tunge løft vil i høj grad blive fri for denne belastning ved hjælp af robotter, detailhandlen og servicefagene vil desuden opleve en markant brug af kunstigt intelligente systemer. Forskning indikerer ligefrem at kunstig intelligens vil overtage 70% af tjenerjobs i USA i 2035. Valgkampe vil blive kæmpet vha kunstigt intelligente modeller. Det et faktum, at Cambridge Analytica har hamstret data fra Facebook-brugere. Mens det måske, måske ikke, er blevet brugt ifbm valgkampe til at præge potentielle vælgere.
Pas på dine data
FNs artikel 12( 1948) om grundlæggende menneskerettigheder:
“No one shall be subjected to arbitrary interference with his privacy, family, home or correspondence, nor to attacks upon his honour and reputation. Everyone has the right to the protection of the law against such interference or attacks.”
Kunstig intelligens er et hamrende relevant emne I 2020.
Mit eksempel med dataindsamlingen af iris-arterne eksemplificere, at data først og fremmest er det accellerende element for en enhver produktion af kunstigt intelligente modeller. Og som tidligere nævnt er det blevet billigt som aldrig før, atproducere kunstig intelligens. Derimod er data ikke billigt. Derfor ser vi også myndigheder og virksomheder benytte sig af uetiske metoder ved enten at købe eller indsamle data fra eksempelvis Facebook og andre tjenester, som vi har betalt for at benytte ved at tillade adgang til vores personlige data.
Virksomheder og myndigheder vil altid garantere os for, at vores data er sikrede. Men faktum er, at datasikkerhed inden for dataindsamling er på et ekstremt skrøbeligt fundament. De er oftest ikke beskyttet af hverken kryptering eller anden type støj, som kan anonymisere vores data.
Min opfordring er derfor, at skolerne bliver mere skarpe på deres data-politiker, og taler med eleverne om data og privatlivets fred, samt respektere, hvis der er elever, som ikke ønsker at downloade apps eller bruge tjenester, som eksempelvis Kahoot, der tæller hele 8 potentielle trackere(*10), som kan indsamle data til statistik, og som er et glimrende eksempel på en tjeneste, som giver os gratis adgang, hvis vi lige betaler dem voresmail eller adgang til vores facebook eller Google-konto, inden vi kan bruge produktet.
Videre forløb
Har man i øvrigt fået lyst til at se nærmere på kunstig intelligens, findes der en super god ressource til dette formål: Machine Learning for Kids, som kræver et basalt kendskab til Scratch: https://machinelearningforkids.co.uk/ . Det er en god kilde til at demonstrere principperne bag kunstig intelligens.
Links
1: https://en.wikipedia.org/wiki/Technological_revolution
2: https://www.dr.dk/nyheder/politik/statsministeren-bebuder-markant-mere-overvagning-i-danmark)
3: http://cogprints.org/499/1/turing.html
4: https://da.wikipedia.org/wiki/Iris-sl%C3%A6gten
5: http://ufldl.stanford.edu/tutorial/supervised/LinearRegression/
6: http://deeplearning.stanford.edu/tutorial/supervised/SoftmaxRegression/
7: https://github.com/atlemgw/folkeskolendk/blob/master/ml_iris.ipynb
8: https://quickdraw.withgoogle.com/shared/c2vW7yM2IyqV#
9: https://www.thispersondoesnotexist.com/
10: De 8 trackere på Kahoot er:
ajax.googleapis.com
www.google-analytics.com
accounts.google.com
apis.google.com
fonts.gstatic.com
ssl.gstatic.com
kahoot.com
www.youtube.com